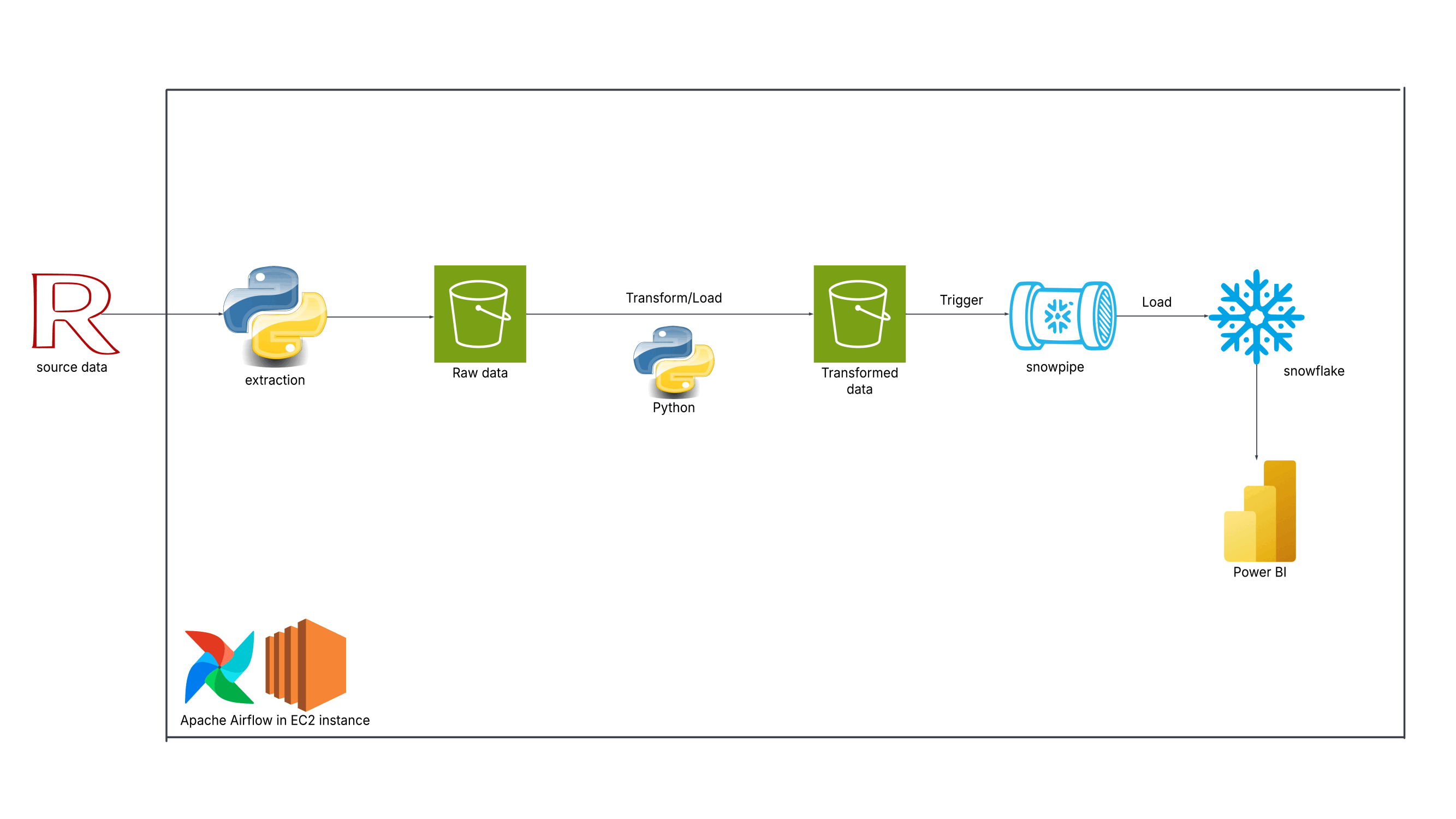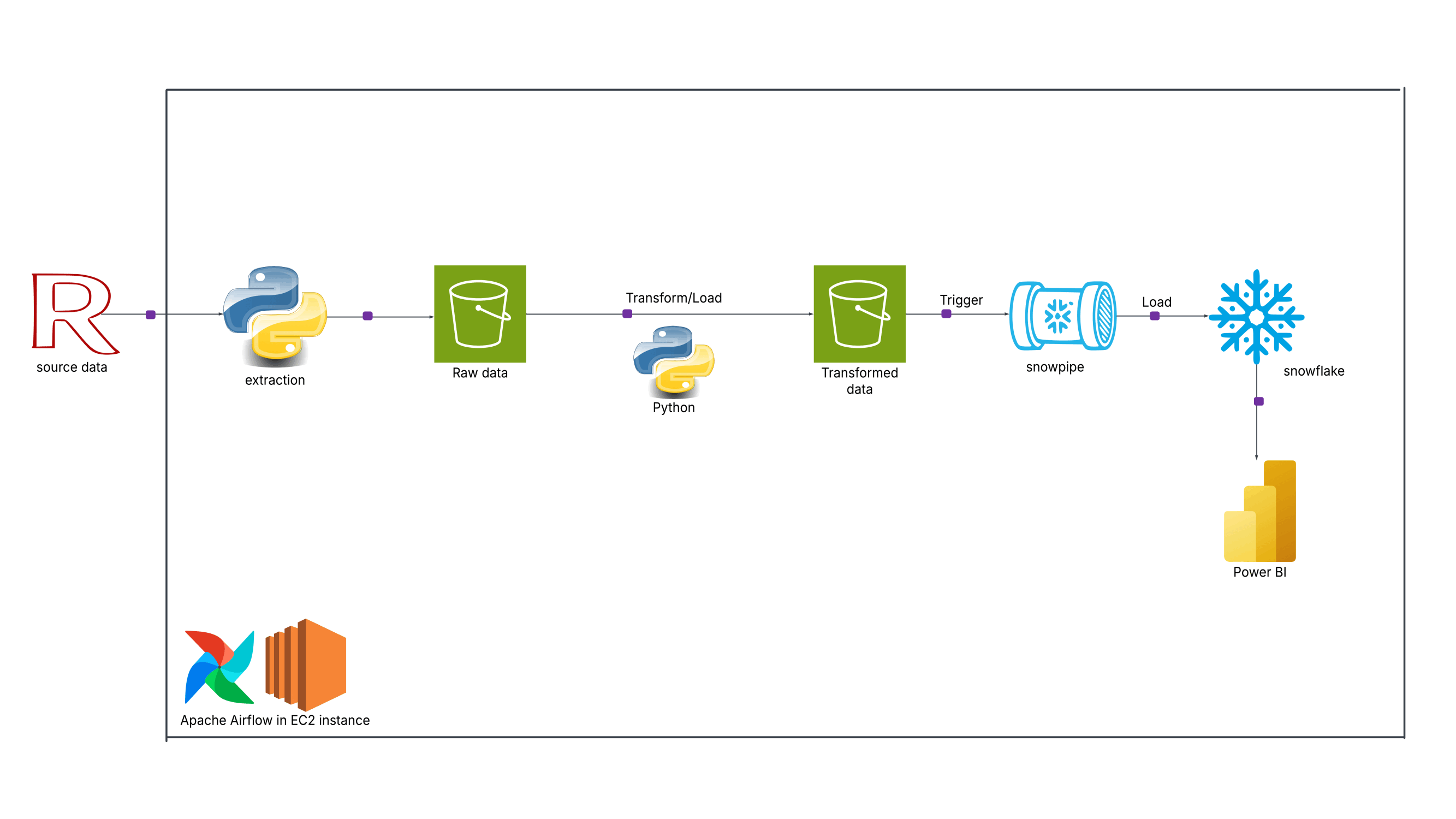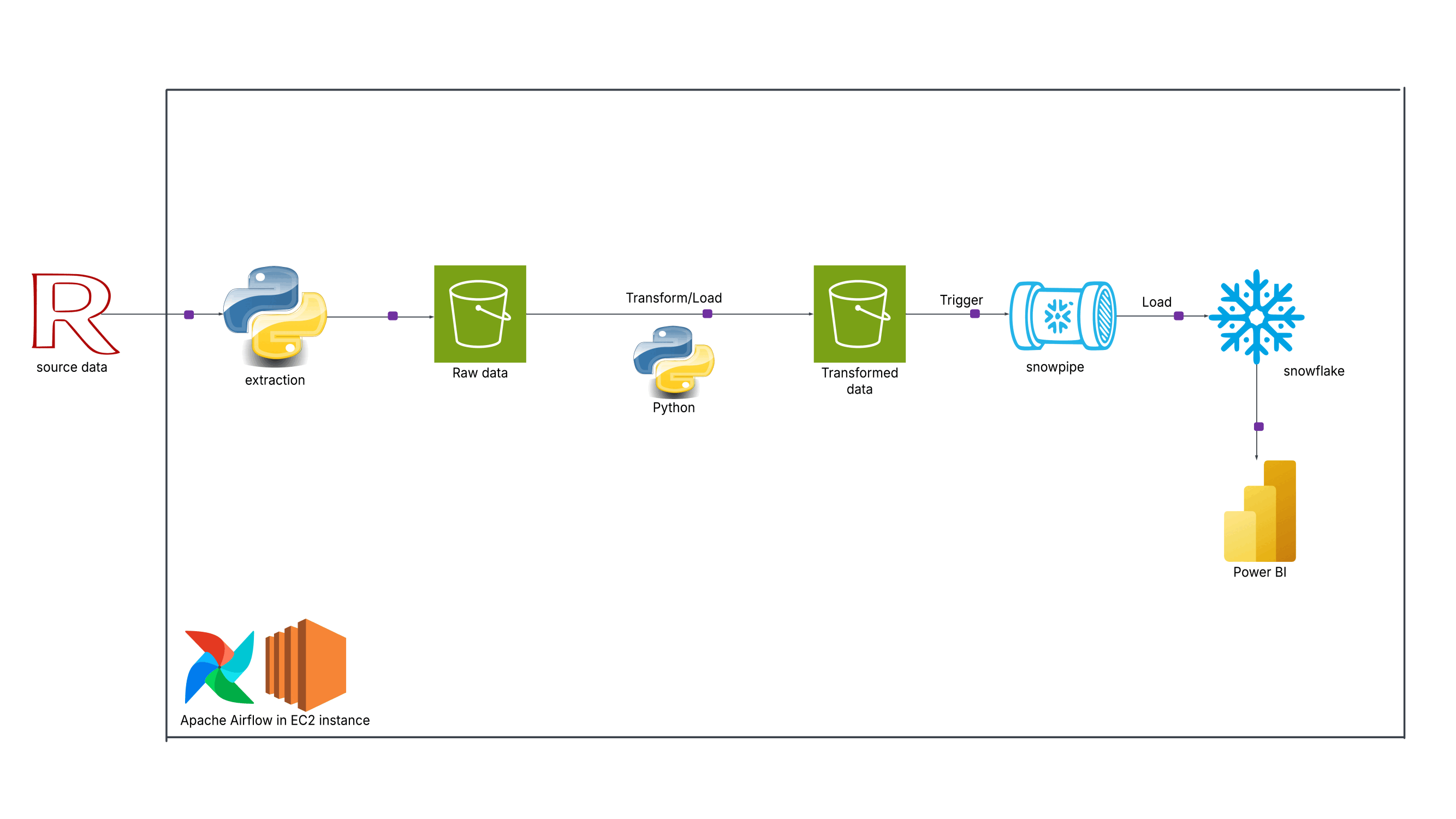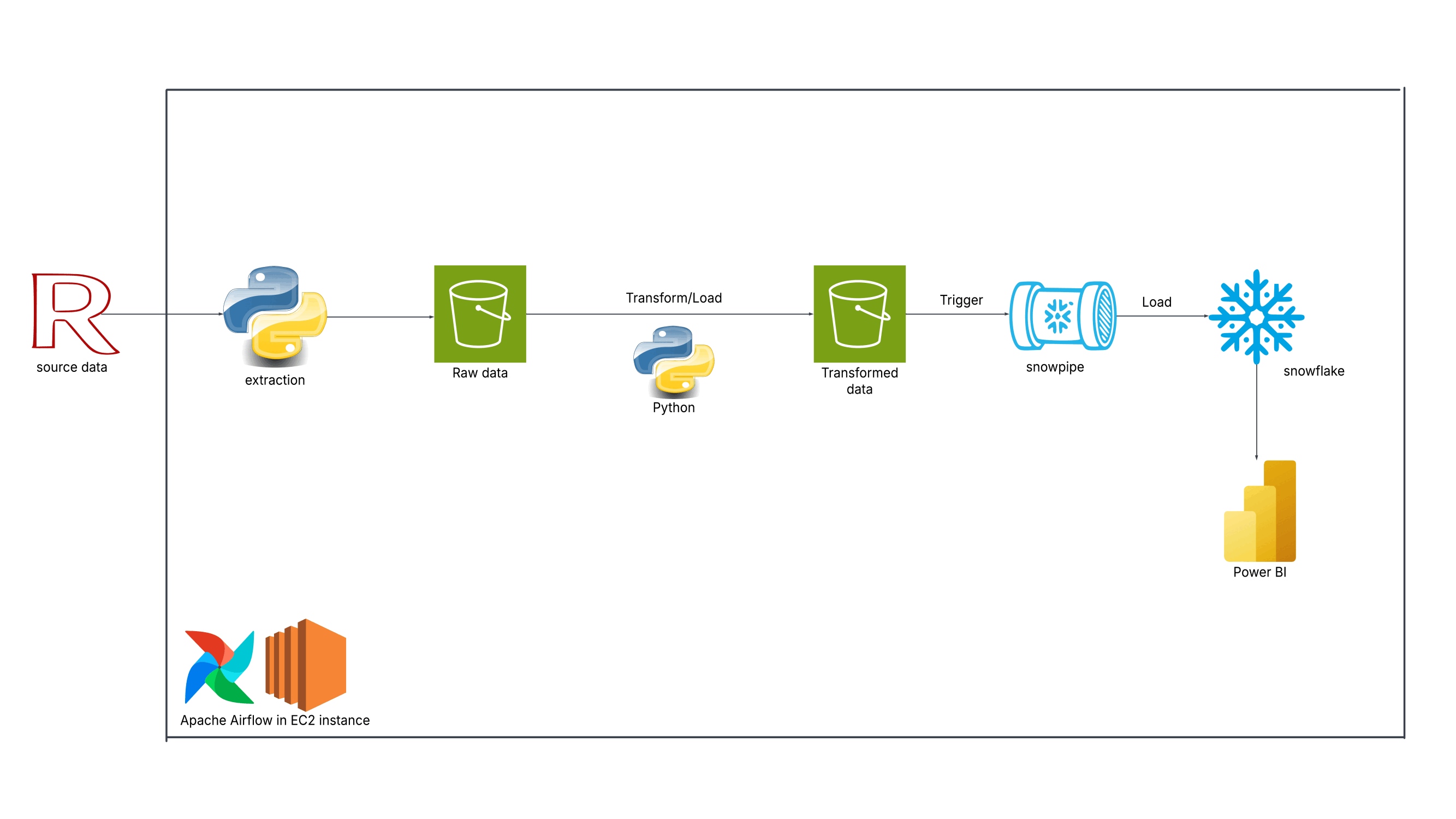
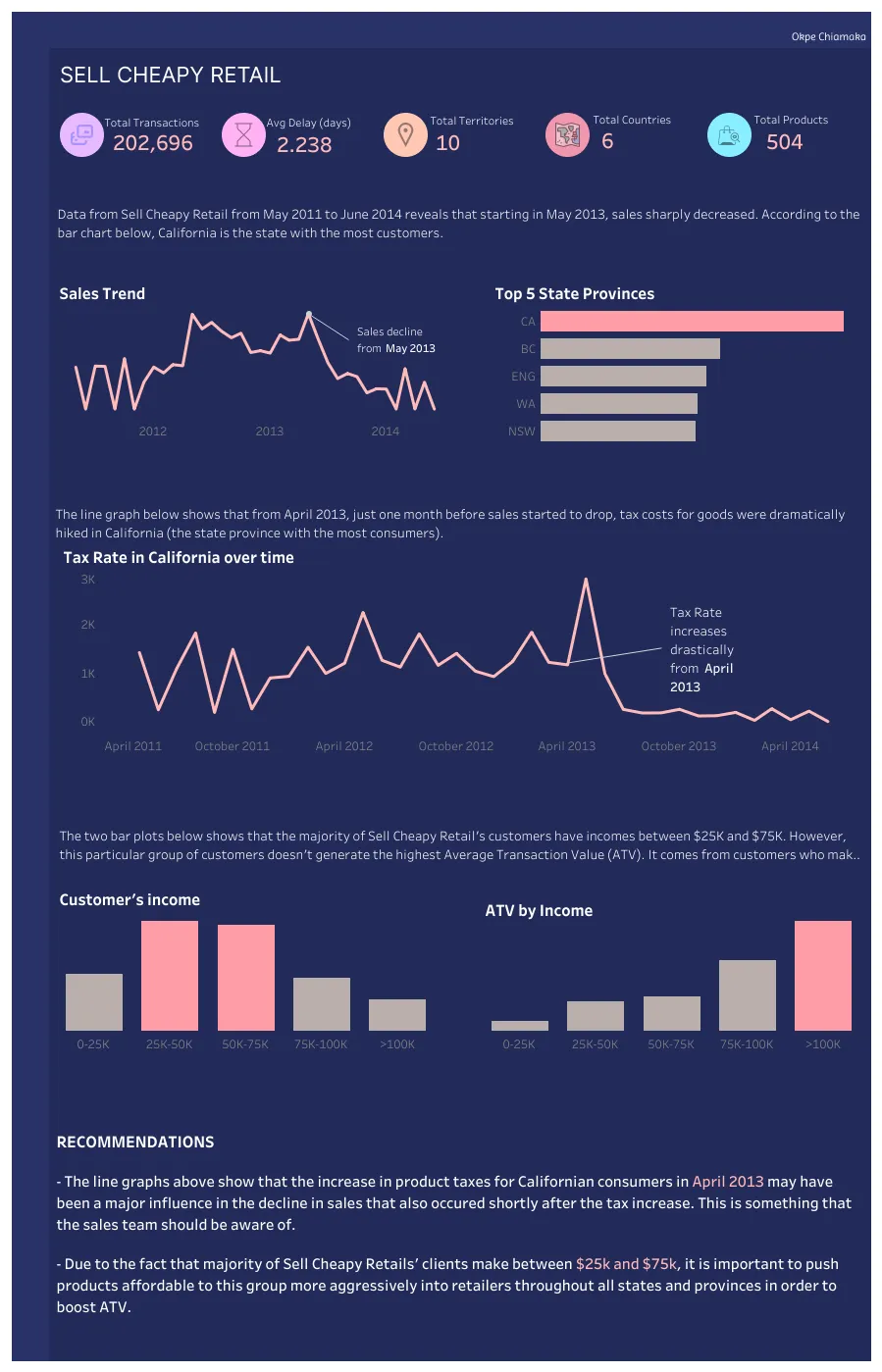
About

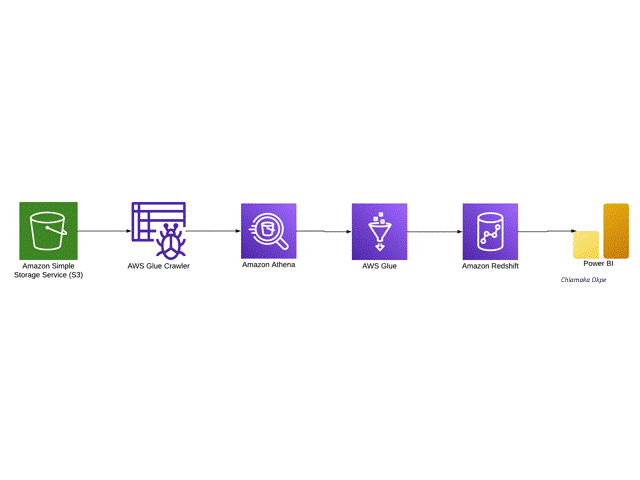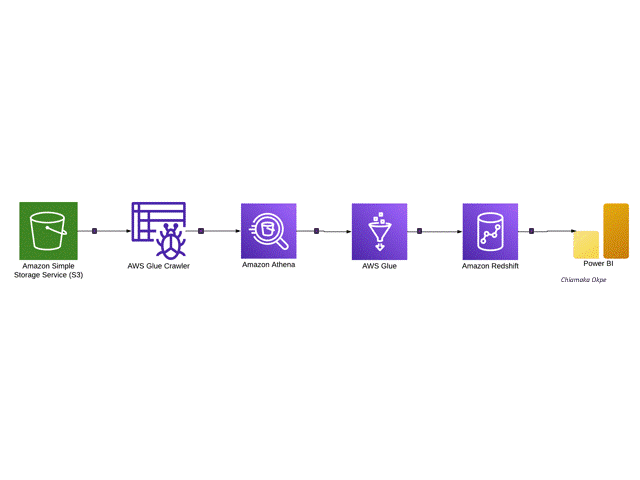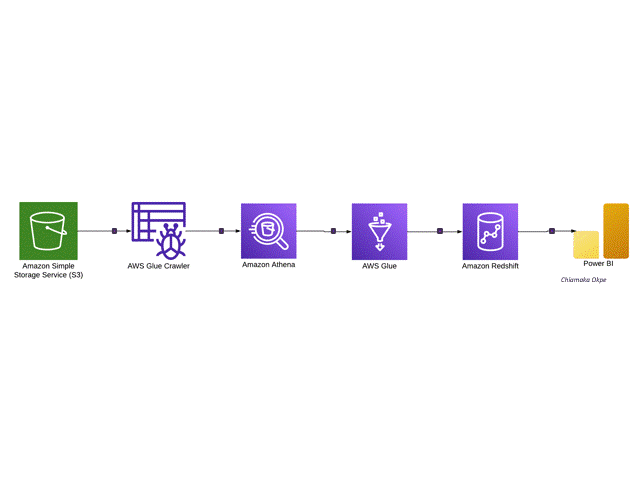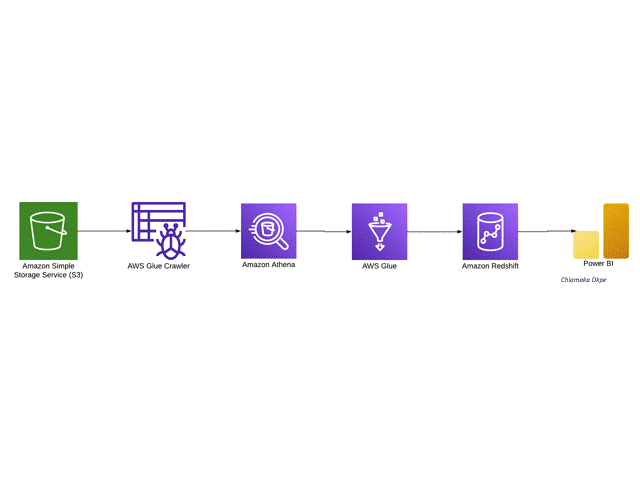
I'm a data professional passionate about turning raw data into actionable insights and automated workflows. I specialize in end-to-end data engineering, building cloud-based pipelines with AWS and Prefect, and developing ETL and machine learning solutions in Python.
Technical Skills: AWS, Prefect, Python, ETL, Data Wrangling, Machine Learning, Cloud Integration, Pipeline Orchestration, Network Analysis, Pandas, NumPy
View Resume